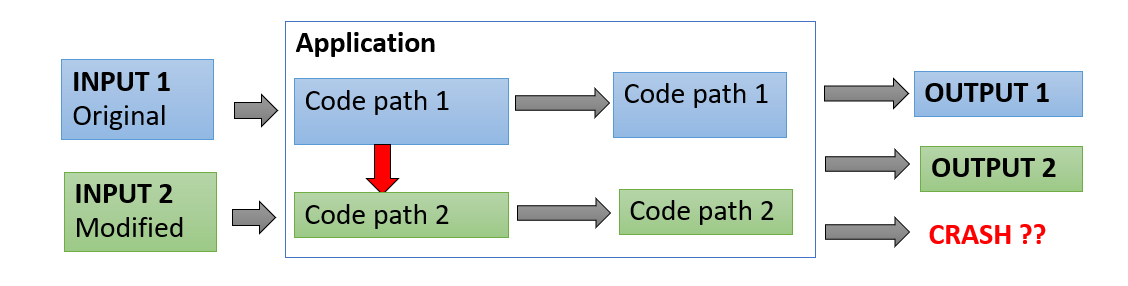
Fuzzing是自动查找错误的过程。摸索器将生成或提供精心设计的程序输入,并监测其行为。如果其崩溃,则可保存测试案例以进一步分析和复现。
有各种类型的模糊测试程序,如:
生成随机输入。
例如: radamsa
https://github.com/hardik05/Damn_Vulnerable_C_Program
你需要很幸运才能用这些模糊测试程序找到复杂程序中的错误。
基于预定义的模板生成输入。
例子: Peach, Sulley.
你可以找到错误,但需要在理解和生成文件模板或网络协议结构方面做工作。
使用编译时或运行时检测程序的执行情况,并能根据所走的路径生成新的输入文件。
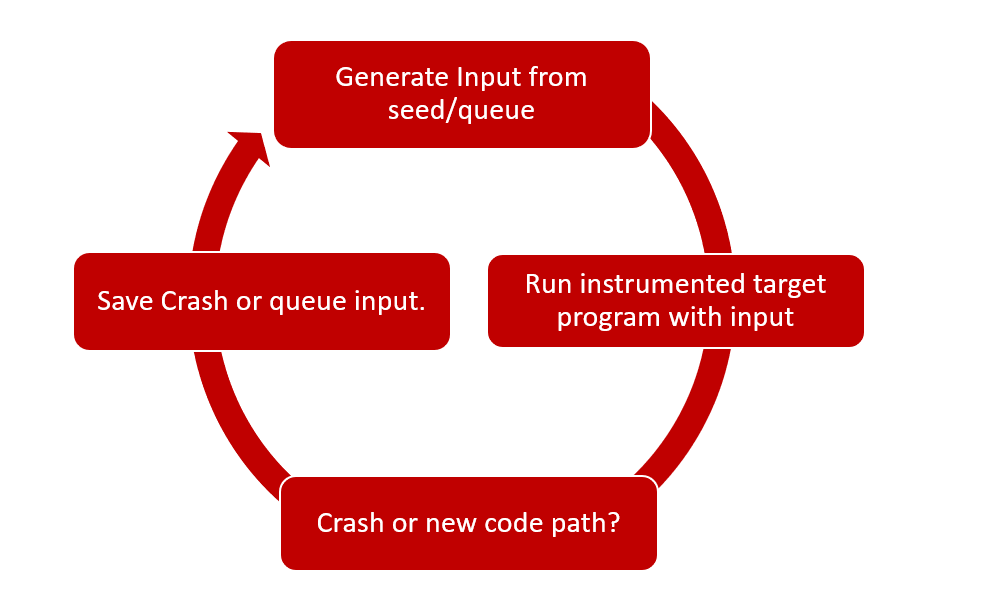
例子: AFL,Honggfuzz,libfuzzer
非常有用,而且成功地找到了错误。
有趣的案例研究
无中生有的jpeg图片: https://lcamtuf.blogspot.com/2014/11/pulling-jpegs-out-of-thin-air.html
$ mkdir in_dir
$ echo 'hello' >in_dir/hello
$ ./afl-fuzz -i in_dir -o out_dir ./jpeg-9a/djpeg请考虑以下代码:
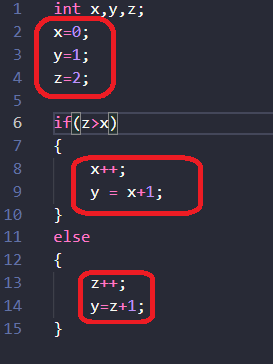
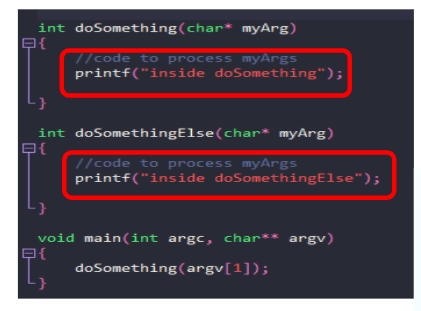
它在IDA中的样子:
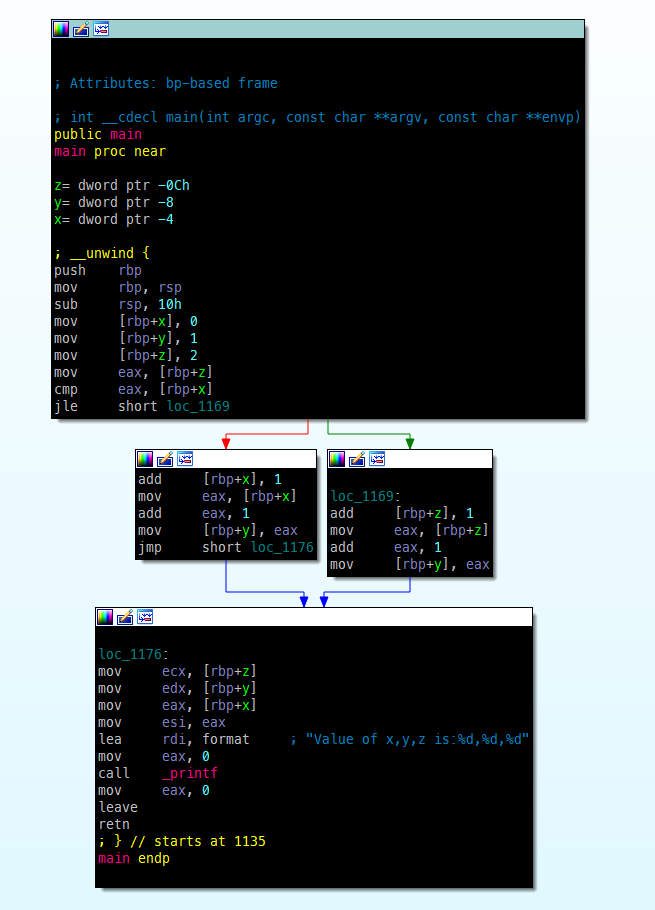
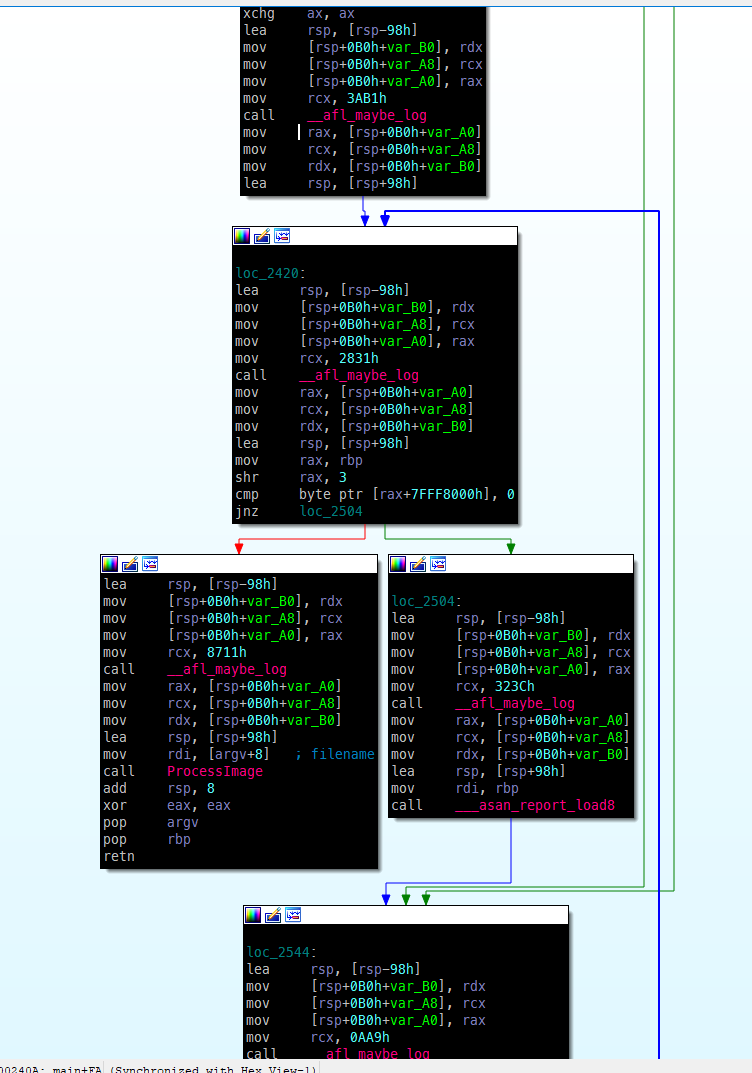
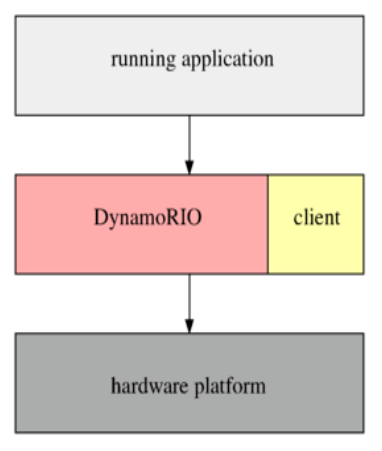
如何在运行时跟踪程序的执行情况,以检查正在采取哪些代码路径?
| 模式 | 详细介绍 |
Fork 服务模式 | 创建进程的副本 |
持久化模式 | 围绕特定的代码行进行循环 |
cur_location = <COMPILE_TIME_RANDOM >;
shared_mem[cur_location ^ prev_location ]++;
prev_location = cur_location >> 1;
A → B →C → D → E vs A → B → D → C → E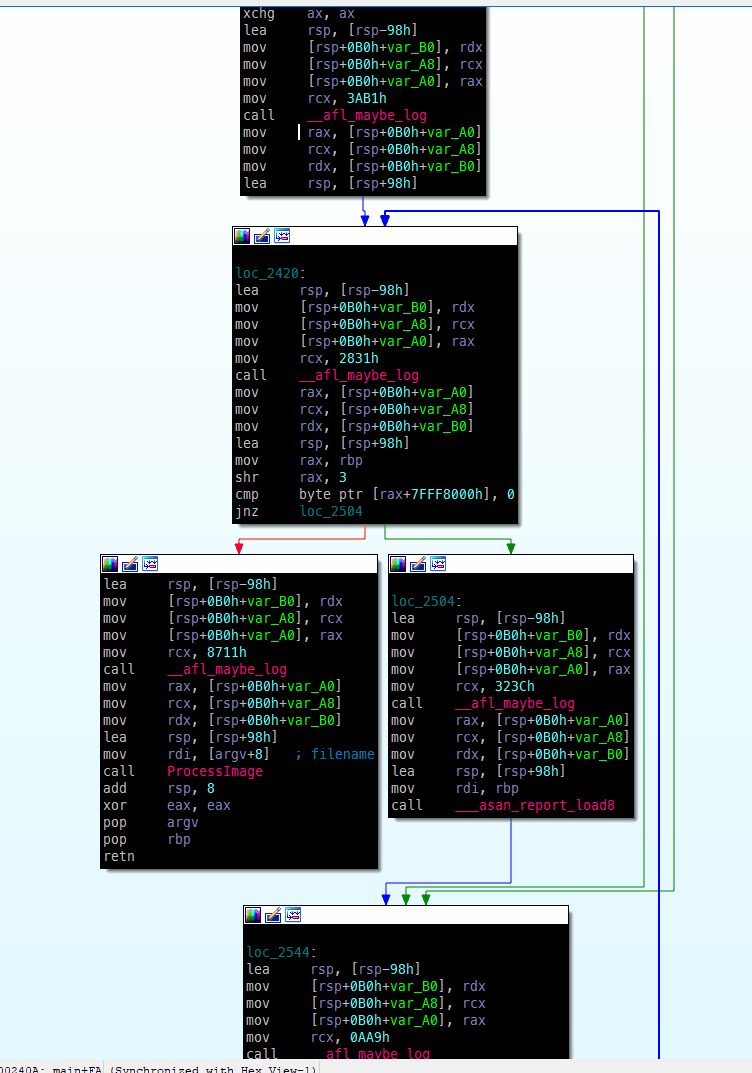
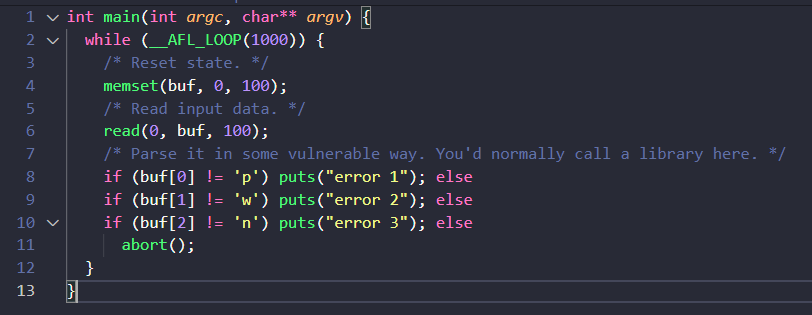
当你想模糊测试程序的某个部分时,这是非常有用的。
参考:
https://lcamtuf.blogspot.com/2014/10/fuzzing-binaries-without-execve.html
https://lcamtuf.blogspot.com/2015/06/new-in-afl-persistent-mode.html]
Fuzzing Strategy | 详细内容 |
Bit Flip | 翻转一位,即1变为0,0变为1-这可以通过1⁄1,2⁄1,4⁄1,8⁄8….的步骤完成。。。。32⁄8(同样的策略也将用于byteflip) |
Byte Flip | 移动一个字节--可以按1⁄1,2⁄1,4⁄1,8⁄8的步骤进行 ....32⁄8 |
Arithmetic | Random arithmetic like addition/substraction of random values |
Havoc | 随机策略-位/字节/兴趣/拼接/加法/减法中的任意内容 |
Dictionary | 用户提供的字典或自动发现的token |
Interest | 用有趣的数值替换原始文件中的内容,比如。0xff,0x7f等 |
Splice | 拆分和合并两个或多个文件,得到一个新的文件。 |
参考资料:
https://github.com/google/AFL/blob/master/docs/technical_details.txt

例如:
为什么我们需要最小化输入语料库?
怎么做?
afl-cmin –i input –o mininput -- ./program @@我们通过进行模糊测试发现了一个崩溃,现在怎么办?
如果我们发现了1-2次崩溃,那么我们可以做人工分析,但如果我们发现了几百次或几千次的崩溃呢?
有各种可用的工具,例如:
Crashwalk, atriage, afl-collect